
Normalization in SQL – Different Types with Examples

Did you know that incomplete or defective data often results in wrong conclusions? Consequently, businesses lose countless opportunities when unorganized data sets derail their marketing strategy. Whether your company offers thousands or millions of products, data organization is essential for profitable and efficient operations.
Sadly, many firms neglect database normalization owing to the duration and commitment required. Fortunately, normalization in SQL provides a remedy to this problem. In this blog, we will learn about normal forms in SQL, their types, examples, and more.
What Is SQL Normalization?
Normalization in SQL is the procedure of removing data redundancy and improving data reliability in a database. It also aids in the organization of data in a database.
SQL normalization structures a database’s columns and tables to guarantee all database integrity restrictions implement their dependencies correctly. It is a method of deconstructing tables to minimize data repetition and undesired characteristics. These characteristics include update, insertion, and deletion anomalies.
The Important Keys for Normalization in SQL
Keys are critical components of any relational database. They recognize every tuple in a table. The super key and candidate key are two keys utilized during SQL normalization.
A candidate key is a set of attributes that recognizes the tuples in a relation or table. On the other hand, a super key uniquely identifies each row table.
Let’s look at them in detail before going on to the normal forms in SQL.
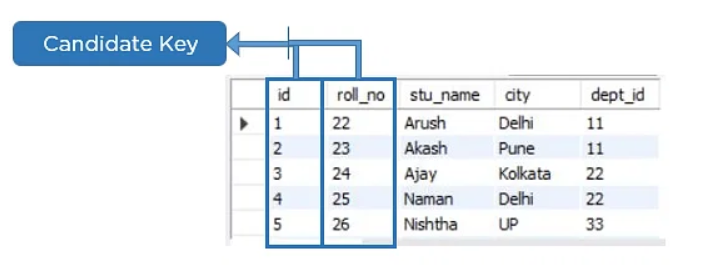
Candidate Key
It is the collection of single or multiple columns employed to identify a record in a database table. You can utilize every candidate key like a primary key.
Let’s look at an example to help you understand this better.
Super Key
It is a collection of more than one key, which can uniquely identify a record within a table. The primary key is a subset of the super key.
Given below is an example of a super key.
Types of Normalization in SQL with Examples
There are mainly four types of Normal Forms in SQL.
These are:
- First Normal Form (1NF)
- Second Normal Form (2NF)
- Third Normal Form (3NF)
- Boyce Codd Normal Form (BCNF)
Given below is a detailed analysis of normalization in SQL with examples.
First Normal Form (1NF)
A table is said to be in its first normal form if its atomicity is 1. Atomicity indicates that a single cell in a table cannot carry multiple values. The cell must only include a single attribute with a single value. The multi-valued attribute, as well as composite attribute, along with their permutations, are not allowed in the first normal form.
Let’s understand this with an example. The table below contains a student’s roll number, name, course, and age.
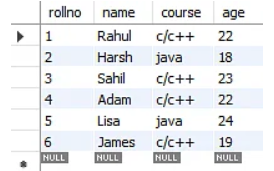
The course column in the student’s record database contains two values. As a result, it fails to adhere to the first normal form. When you apply the first normal form to the preceding table, you obtain the result shown below.
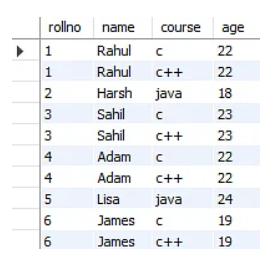
You accomplish atomicity by using the first normal form. Each column contains distinct values.
Second Normal Form (2NF)
The table must first be in its first normal form before getting converted to its second normal form. Along with that, the table shouldn’t have any partial dependencies. The partial dependency indicates that the appropriate subset of a candidate key must return a non-prime attribute.
Given below is an example of the second normal form. Consider the following table:
The location table has a primary key composite of cust id and storeId. The store location is a non-key attribute. It is dependent on storeId, a component of the primary key. As a result, this table does not satisfy the second normal form.
To convert the table to the second normal form, divide it into two halves. This will yield the following tables:
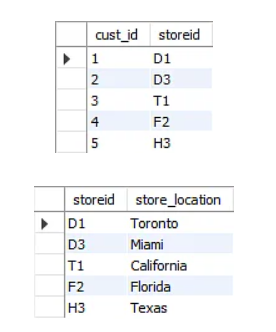
Since we eliminated the partial functional reliance from the location table, the column store location is dependent on the table’s primary key, storeid.
Third Normal Form (3NF)
The first requirement for a table to belong to the third normal form is it should be in the second normal form. The second criterion is that there cannot be a transitive reliance on non-prime attributes. It means that non-prime attributes that are not components of the candidate key, must not be dependent on other non-prime attributes. To learn more about normalization in SQL, you can opt for a comprehensive SQL Course.
A transitive dependency is thus a functional relationship in which A -> C (A determines or decides C) indirectly as a result of A -> B and B -> C, where B -> A is not the case.
The third normal form in SQL minimizes data duplication. It is additionally employed to ensure the integrity of data. Let’s understand it with an example. Given below is a table with the student id and student name.
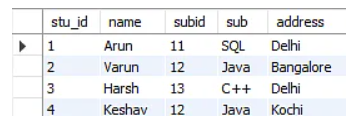
In the student table above, stu_id generates subid, and subid gives sub. As a result, stu_id derives sub using subid. This means the table has a transitive functional dependency that fails to meet the third normal form criterion.
Now, to convert this table to the third normal form, divide it as indicated below:
As seen in both tables, every one of the non-key attributes is completely functioning and relies solely on the primary key. Columns name, subid, and addresses within the initial table are dependent on stu_id. The sub solely depends on the subid in the second table.
Boyce Codd Normal Form (BCNF)
The Boyce Codd Normal Form, also called 3.5 NF, is the remastered edition of 3NF. It was created by Raymond F. Boyce and Edgar F. Codd to address specific types of anomalies that 3NF could not resolve.
The first requirement for a table to adhere to the Boyce Codd Normal Form is that it must be in the third normal form. Second, each Right-Hand Side (RHS) characteristic of the functional dependencies must depend on the table’s super key.
Let’s take an example. There is a functional dependency X Y. In the specific functional dependency, X must be a member of the given table’s super key.
Consider the subject table below:
The following conditions apply to the subject table:
- Each student may take various disciplines or subjects.
- A subject can be taught by multiple professors.
- It allocates a professor to each subject and the student.
The primary key in the preceding table is student id and subject since you can discover all table columns with student id and subject. Another aspect to remember is that every professor teaches just one subject, although two professors may teach the same subject. It indicates a dependency between the subject and the professor, i.e., the subject is dependent on the professor’s name.
The given table is in first normal form because all of the columns are distinct and all entries are atomic. Also, every one of the values put in a column has an identical domain. Due to the absence of partial dependence, the table likewise fulfills the second normal form. Furthermore, there isn’t any transitive dependency, so the table follows the third normal form too.
Except for the Boyce Codd Normal Form, the given table reflects all of the normal forms. The main key is formed from stuid and subject, indicating that the subject attribute covers the prime attribute. There is, however, another dependency, the professor -> subject.
Because a subject is indeed a prime attribute, while the professor becomes the non-prime attribute, the Boyce Codd Normal Form does not appear in the table.
To convert the table to the BCNF format, divide it into two sections. The first table will have an existing column stuid, while the second section will contain a freshly formed column profid.
And the columns in the second table, including profid, subject, and professor will satisfy the BCNF.
Advantages of Normalization
Some of the advantages of normalization are:
- Decreases Data Redundancy: The main purpose of normalization is to eliminate duplicate data in relational databases. This, in turn, reduces the amount of storage space needed, improving database efficiency.
- Simplifies Database Design: The normal forms are like guidelines to organize tables and relational data. This simplifies the database design and maintains data for a longer time.
- Supports Data Updates: Any change in data can be done in one place rather than applying the changes to multiple places in a database. Thus, normalization eases the database update process.
- Enhances Query Performance: The application of normalization guidelines to the tables results in easier and quicker database queries, like search, modification, or retrieval of data.
- Better Data Consistency: The reduction in data redundancy naturally decreases the possibility of inconsistencies and errors in data and helps in organizing the data.
- Easy Database Maintenance: Since normalization reduces data redundancy, simplifies the design, and upholds data consistency, all of these positive contributions make database maintenance simpler.
Disadvantages of Normalization
Some of the disadvantages of normalization are:
- Increases Database Management Complexity: The complexity of managing a database arises when normalization is applied to complex database models or when the normalization process is not carried out properly. When trying to maintain and update the database over time, this could result in problems.
- Limits Flexibility in Data Change: The database becomes less flexible to any change because applying normalization requires data to be set up in a specific way. This can make it hard to handle changes in the data or to create new applications that need different ways of organizing data.
- Needs More Storage: While normalization helps reduce data redundancy, it can result in a database needing more room to store data. This is because the data may need to be assembled using additional tables and steps. Therefore, it requires more hardware to support the database, making it more complex and costly.
- Impacts Query Performance: Normalization may cause a database to perform more joins and additional steps to combine data, which could take longer. As a result, queries might execute more slowly.
- Disrupts the Data Context: Normalization might make it harder to understand how different pieces of data are related since the data might be spread out across many tables. This will require the use of extra joins to bring them together.
Conclusion
In this blog, we explored normalization in SQL and the various normal forms of normalization. It helps structure the information stored in the database, removing redundancy and promoting data integrity. Furthermore, it is a great tool for businesses to achieve profitable and efficient solutions.
FAQs
1NF: It is called the First Normal Form and is the most basic level of normalization. In 1NF, there should only be one value in each table cell and a distinct name for each column.
2NF: It is called the Second Normal Form. In 2NF, each non-key attribute needs to be dependent on the primary key, which means that no two columns should be related indirectly to one another but rather directly to the primary key.
3NF: It is known as the Third Normal Form. It builds on 2NF by requiring independent non-key attributes, ensuring columns are directly related to the primary key.
The following are the six rules of normalization.
First Normal Form (1NF)
Second Normal Form (2NF)
Third Normal Form (3NF)
Boyce-Codd Normal Form (BCNF)
Fourth Normal Form (4NF)
Fifth Normal Form (5NF)
By removing the partial dependencies, 1NF can be converted to 2NF. A partial dependency is removed by placing the partially dependent attribute(s) in another relation along with a copy of their determinant (if there is one).
The Boyce-Codd normal form is an extended version of the third normal form in database normalization. It is the highest and the most efficient form of normalization as it removes the condition that the right-hand side of the functional dependency in the 3NF may be a prime attribute.
A primary key in a database management system is a column (or set of columns) that holds values that uniquely identify each row in a table.




